Image Classification
Introduction
In practical terms, Image Classification1 is the task of assigning the correct category label to an image among a set of category labels (Standford University, 2017). In a way analogous to the human vision system (Tanaka & Taylor, 1991), the classification task can be performed at different levels of specificity. Objects can be recognised using:
basic-level category labels (e.g. distinguishing a dog from a cat), which is also the first class of names that children learn;
superordinate-level category labels (e.g. distinguishing an animal from furniture);
subordinate-level category labels (e.g. distinguishing dog breeds), which is only possible with greater expertise.
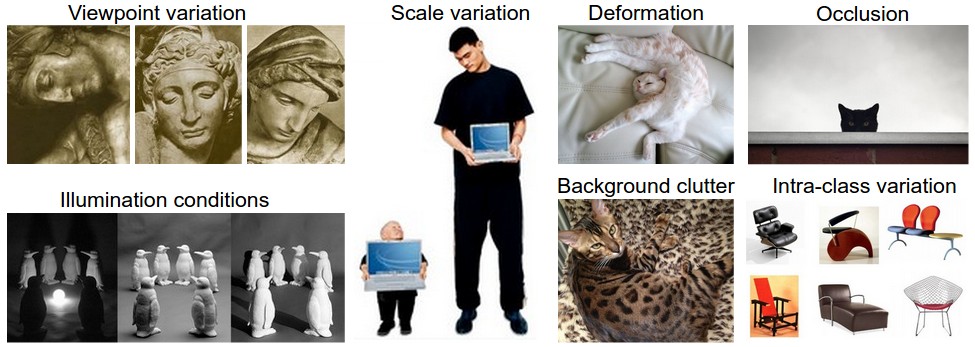
For humans, recognising an object at different levels of specificity is seemingly trivial to perform. In computer vision, however, this is still one of the dominant problems. As outlined by Biederman (1987) in his paper "Recognition-by-Components: A Theory of Human Image Understanding", there are many variations that humans are able cope with when performing image classification. Some of these variations are described below and illustrated in Figure 1; they represent challenges that a computer vision algorithm must overcome:
Viewpoint invariance. The orientation of an object in respect to the viewer can vary.
Occlusion. Only a small portion of the object could be visible.
Deformation. The object could be articulated, possibly deformed in extreme ways.
Intra-class variation. There could be many variations to the physical aspect of an object (e.g. different types of chairs or even a drawing of a chair).
Scale variation. The size of the object could vary (e.g. cat vs kitten).
Background clutter. An object may blend into its environment, thus being harder to identify.
Illumination conditions. Different illumination causes an object to look different at the pixel level.
Functioning Model of an Image Classifier
In computer vision, Image Classification essentially consists of taking a single image - represented as an array of pixels - and assigning a label to it. From a classic machine learning algorithm standpoint, the components required to build an image classifier are formalised as follows:
Data Collecting. A set of N images is gathered, each labelled with one of K different classes. This data is known as the training set.
Preprocessing. The images are encoded into vectors of values (feature vectors) in order to be consumed by an algorithm.
Learning. The vectorised training set is used to learn what the image classes look like. This step is known as learning or training.
Evaluation. The quality of the classifier is evaluated by making it predict labels for a new set of unseen images. The true labels of these images are then compared to the ones predicted by the classifier. Intuitively, the aim is that the predicted classes match up with the true classes (also known as ground truth).
Progress in Image Classification
Image Classification has been long limited by the power that computing systems were able to offer, however, with the advent of modern GPUs and the rise of Big Data, new paths for tackling this task have been explored. The state of the art makes use of Deep Learning and specifically CNN; these perform extremely well since they can exploit inherent properties of images, which also allows for faster training. CNNs are further discussed in the next chapter.
Before analysing this type of network, it is useful to understand some of the concepts it builds on. These are explained in the following section.
Footnotes
1. The terms Image Classification and Object Recognition are often used interchangeably. There seems to be confusion regarding the naming convention, however, one common viewpoint is that Image Classification relates to the task or problem, while Object Recognition relates to the method or process through which this task is carried out. ↩
References
- Standford University. (2017). Stanford university cs231n: Convolutional neural networks for visual recognition. CNN Notes.
- Tanaka, J. W., & Taylor, M. (1991). Object categories and expertise: Is the basic level in the eye of the beholder? Cognitive Psychology, 23(3), 457–482.
- Biederman, I. (1987). Recognition-by-components: A theory of human image understanding. Psychological Review, 94(2), 115–147.